DataOps Principle #10: Orchestration
In my last two entries I explained a way to integrate Power BI dataflows into source control and then write test cases using the Gherkin-language. If you’ve read some of the prior entries, you may probably know where this article is going… orchestration.
DataOps Principle #10 - The beginning-to-end orchestration of data, tools, code, environments, and the analytic teams work is a key driver of analytic success.
Orchestration requires a level of automation, so with that in mind, I focused on automating three parts:
1) Figure out a way to manage a roll-back to a prior version of the dataflow in source control so the Power BI service could be updated automatically.
2) Automate the testing and publishing of test results.
3) Script-out the configuration to make it easy to setup new projects in the future.
The Challenges
Figure out a way to manage a roll-back to a prior version of the dataflow in source control so the Power BI service could be updated automatically
I didn’t anticipate #1 to be so difficult. I was faced with several challenges I’d like to share:
1) There is no easy way to discern through git history if a new push (an update to the repository in Azure DevOps) is actually a roll-back. I scoured several Stack Overflow threads and there is quite a history of colleagues trying to do the same thing. The most straightforward answer I could come up with was to start the commit message with “Revert:” and use a regex (always love a chance to use regex) to handle this situation.
2) As of August 2022, dataflows are owned by one user, and back when dataflows were made generally available, Microsoft provided the ability to take over ownership in the interface. So, my plan was to take over the dataflow with my service account running in Azure DevOps and replace it with the revert version. I made sure my service account had admin rights to the workspace with the dataflow and then looked for the API endpoint to take over ownership in a dataflow. I knew one existed for taking over a dataset, so in 3 years surely there would be one for taking over ownership in a dataflow. I was wrong. I resorted to network snooping with Developer Tools on the browser and found Microsoft uses an internal API call to do it: https://wabi-us-east2-b-primary-redirect.analysis.windows.net/metadata/dataflows/xxxxx-xxxx-xxxx-xxxx-xxxxxxxxx/takeover. It does exist, but is not available to the public (sigh). I know I’m not the only one with this issue… please up-vote this suggestion on Power BI ideas.
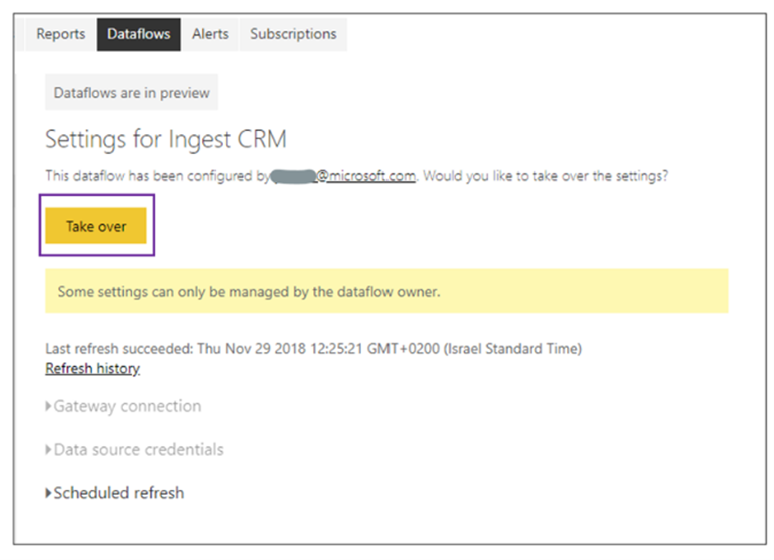
Figure 1 – Example from Microsoft on taking over a dataflow in the Power BI Service. But no API endpoint to do the same ☹
3) Then I thought I’d be slick and use the Bring-Your-Own-Data-Lake I needed for the source control piece and just update the model.json there. Well, no luck there either. You can update the model.json but those changes are not reflected in the service or, if they are, do not immediately update the service which would be problematic.
I left feeling a little defeated and decided to address this later when either the API endpoint is made available, or some other suggestions come up that spark a solution.
Automate the testing and publishing of test results.
At this point I was hoping for an easy win to lift my spirits. The challenge I needed to overcome was allowing a service account to run the tests AND have access to the data lake in order to run tests on the partitions. Thankfully Azure DevOps offers that ability with an Azure Resource Manager Service Connection. This creates an app service principal I can use to grant read access to the data lake. Then with the help of an Azure PowerShell script task, I can run the Invoke-Gherkin command (I explained this command in Part 21 to run the tests. Thankfully, the next step to publish the test results was even simpler. Since the Invoke-Gherkin command produces test results in the NUnit format, we can use the built in “Publish Test Results” step and load the results into our test results library.
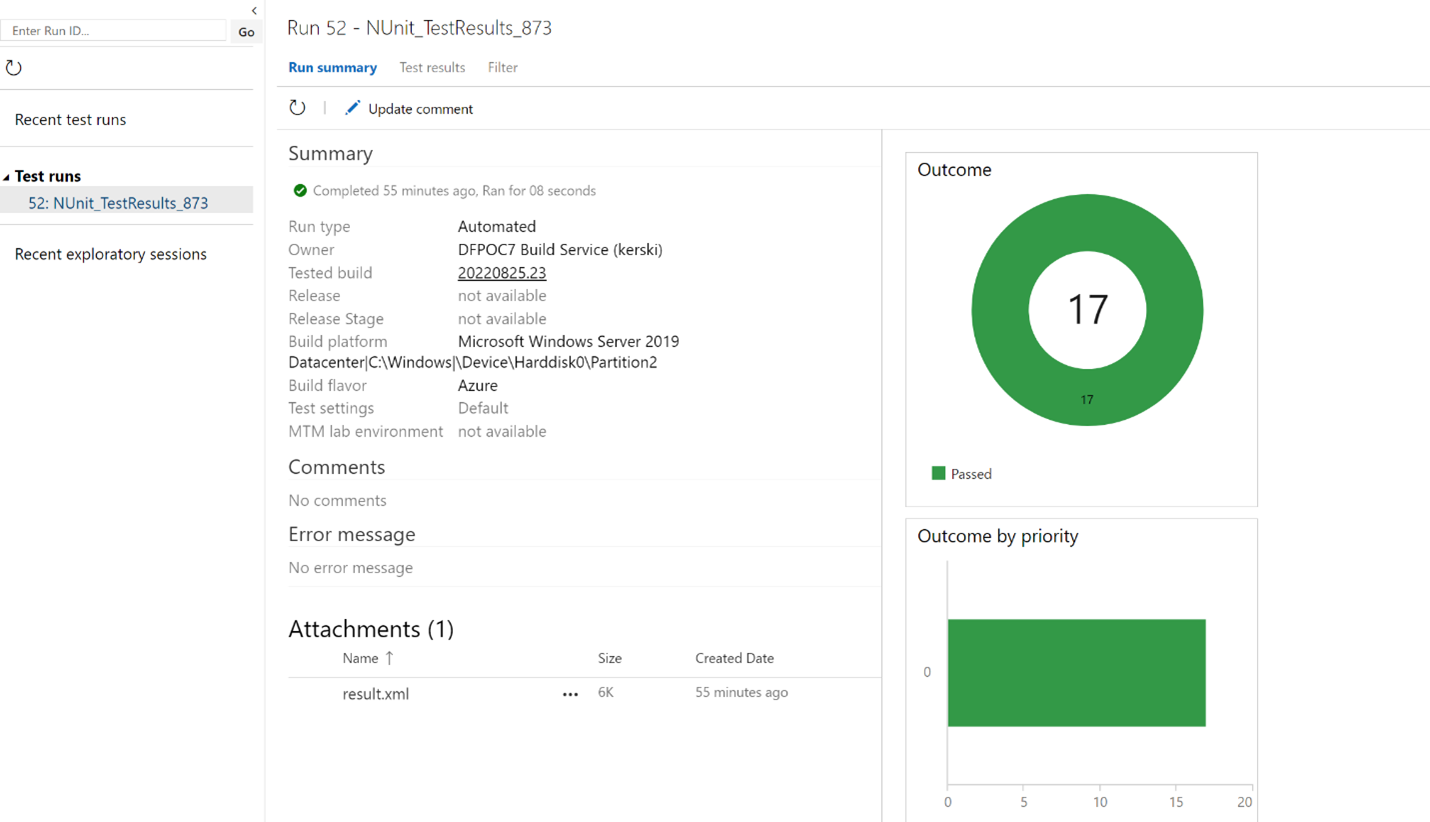 Figure 2 – Example of loaded test results in Azure DevOps
Figure 2 – Example of loaded test results in Azure DevOps
Script-out the configuration to make it easy to setup new projects in the future.
Alright, so I anticipated this objective was going to be a challenge. From prior projects I had built scripts to automatically setup an Azure DevOps project and pipeline, but never before had I created the Azure Resource Manager Service Connection with the Azure CLI. At first, I read the Microsoft documentation which offered ambiguous guidance on using the Azure CLI. I then turned to blogs written by colleagues who may have posted on the topic. After reading articles by Rodney Almeida and Sander Rozemuller I was ready to experiment. After a few rounds of trial-and-error I figured out that I needed to use the Azure CLI to create an app service principal first, make sure it had explicit read rights to the Azure Data Lake and then setup the Azure DevOps Service Connection using the service principal I created. There may be a better way to do this, but I got consistent results using this script, so that was good for now.

Figure 3 – The incantation I needed to automate the creation of an Azure Resource Manager Service Connection
Orchestration
Well, completing 2 out of 3 automations isn’t bad, so here is a visual of the orchestration in action.
I’ve highlighted the new parts to this process in the image below and here’s what they do:
1) The Azure Pipeline sees an update to the repo has occurred and starts the build.
2) The Azure Resource Manager Service Connection is used to run the task that calls Invoke-Gherkin.
3) All test cases in the project are ran and the results are stored in the Test Plans component of Azure DevOps for review.
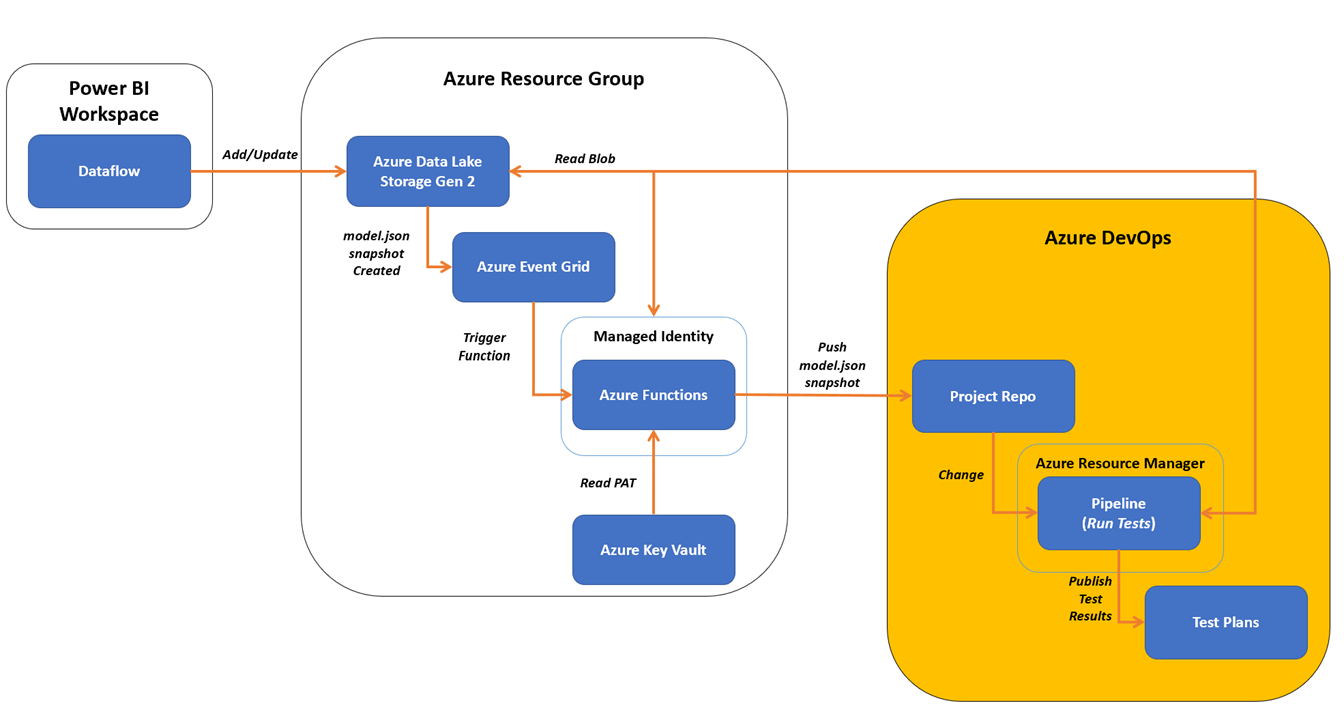
Figure 4 – New automations highlighted
Sharing The Proposed Solution
I’ve shared my code and instructions on how to setup and orchestrate a build with a sample dataflow on GitHub. My hope is that you can leverage these samples to start to build a suite of dataflows backed by source control, tested using an easy-to-use framework, and automated through orchestration.